Documentação Técnica: Pipeline de Ingestão de Artigos (ETL Blog)
1. Visão Geral
Este subsistema é responsável por extrair, limpar e estruturar o conteúdo técnico do Blog da Contabilizei. O objetivo é transformar páginas HTML não estruturadas em arquivos Markdown de alta fidelidade, preservando tabelas tributárias, datas de atualização e links de vídeo, para alimentar a base de conhecimento do sistema RAG.
A solução utiliza uma abordagem híbrida: processamento Python para limpeza pesada e extração de metadados, combinado com LLM para estruturação semântica.
2. Arquitetura e Fluxo de Dados
O pipeline opera em lote (batch processing), lendo URLs de uma planilha e gerando arquivos organizados por diretórios.
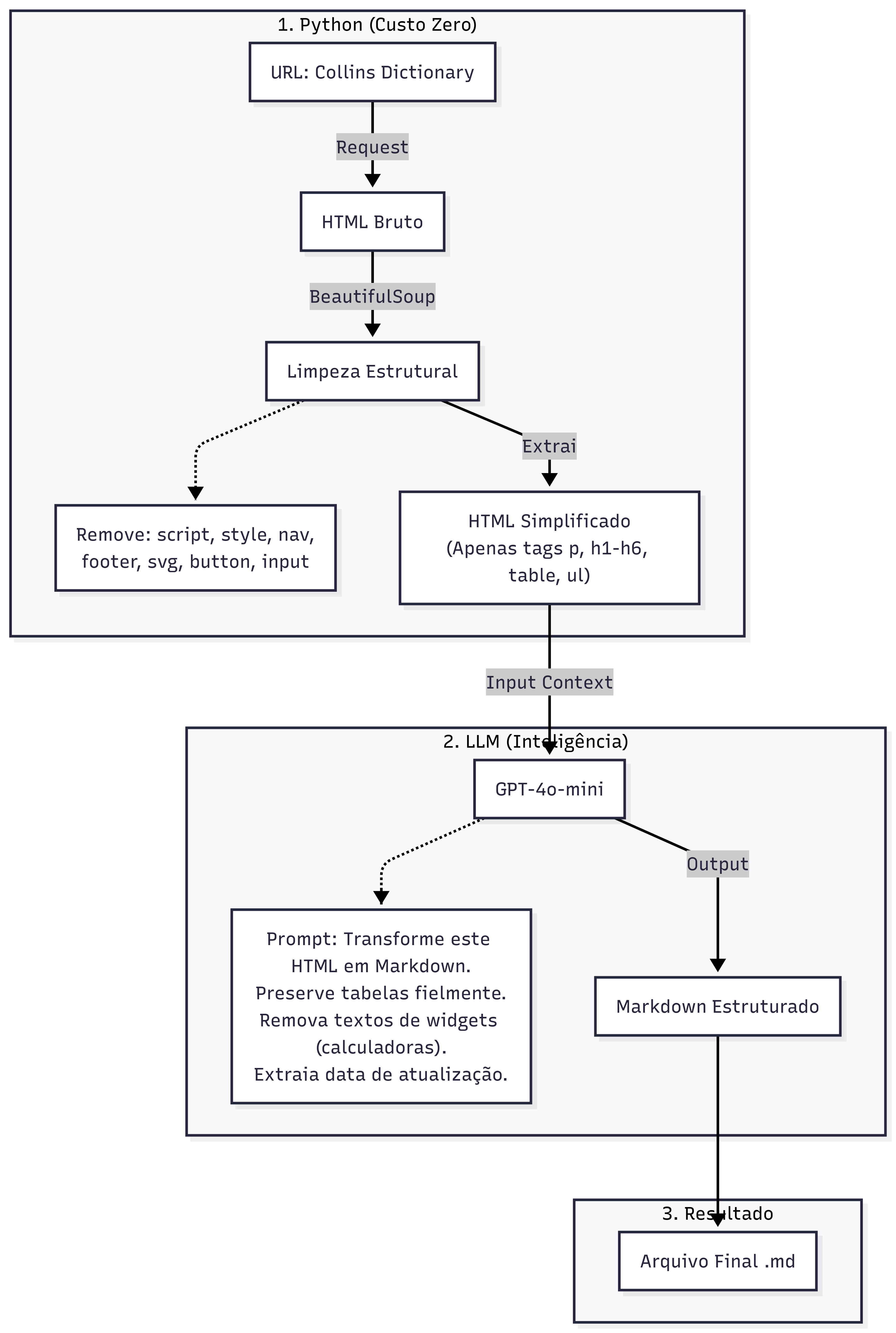 Figura 1: Arquitetura Lógica do Pipeline de Blog
Figura 1: Arquitetura Lógica do Pipeline de Blog
O Fluxo Passo a Passo:
- Ingestão: O orquestrador lê o arquivo
urls_blog.csv. - Request & Validação: Verifica se a URL é válida e se a página está acessível (Status 200).
- Extração de Metadados (Python): Antes de limpar o HTML, o script busca a "Fonte da Verdade" da data (
article:modified_time) nos metadados da página. - Limpeza de DOM (Python): Remove elementos de UI, banners, calculadoras e menus que poluem o contexto.
- Estruturação Semântica (LLM): O HTML limpo é enviado ao GPT-4o-mini, que converte o conteúdo para Markdown, garantindo que tabelas HTML complexas sejam transformadas corretamente.
- Persistência: O Markdown gerado é salvo com um cabeçalho YAML (Frontmatter) rico em metadados.
3. Lógica e Decisões Técnicas
3.1. Abordagem Híbrida (Python + LLM)
Optamos por não enviar o HTML bruto diretamente para a LLM, nem usar apenas scrapers tradicionais.
- Python (BeautifulSoup): É usado para limpar o HTML bruto. Removemos scripts, estilos e menus de navegação programaticamente. Isso reduz o consumo de tokens e o custo da API.
- LLM (GPT-4o-mini): É usada especificamente para formatação. Scrapers comuns falham ao converter tabelas complexas (como Anexos do Simples Nacional). A LLM entende a estrutura visual da tabela HTML e a transcreve perfeitamente para Markdown.
3.2. Preservação da Data de Atualização
A data visível no texto do blog nem sempre é confiável ou fácil de capturar via Regex (formatos variados).
- Solução: Extraímos a data diretamente da meta-tag
<meta property="article:modified_time">. Você consegue verificar a sua existência a partir do script "inspect_html.py". - Por que: Isso garante que o RAG saiba exatamente a data da informação fiscal. Se a LLM alucinar uma data no texto, o script Python sobrescreve com a data real do metadado.
3.3. Idempotência (Smart Resume)
O script verifica se o diretório de saída daquela linha (ex: linha_003) já existe e contém arquivos. Se sim, ele pula o processamento. Isso permite reiniciar o script após falhas de conexão sem duplicar custos ou arquivos.
4. Ferramentas de Diagnóstico: inspect_html.py
Criamos um script auxiliar chamado inspect_html.py para garantir a qualidade antes da execução em massa, nele podemos especificar qual é a URL que queremos inspecionar.
Para que serve: Ele simula a etapa de limpeza do pipeline em uma única URL e gera dois arquivos locais dentro da pasta debug_html_output:
1_original_full.html: O site como ele é.2_cleaned_for_llm.html: Exatamente o que será enviado para a LLM.
Por que usamos:
É fundamental verificar o arquivo 2_cleaned_for_llm.html para garantir que não removemos conteúdo útil (como uma tabela importante) ou deixamos lixo (como um banner de propaganda) antes de gastar dinheiro com a API.
5. Exemplo de Output
Cada artigo gera um arquivo .md com Frontmatter (metadados para indexação) e corpo estruturado.
Exemplo Real (Linha 003 do CSV):
Arquivo: base_rag_blog/linha_003/blog_Como_pagar_menos_impostos_sendo_PJ_.md
---
source_row: 3
title: "Como pagar menos impostos sendo PJ?"
url: "[https://www.contabilizei.com.br/contabilidade-online/como-pagar-menos-impostos-sendo-pj/](https://www.contabilizei.com.br/contabilidade-online/como-pagar-menos-impostos-sendo-pj/)"
date: "2026-01-13"
tags: ['impostos', 'PJ', 'planejamento tributário', 'Simples Nacional', 'Fator-R']
summary: "Este artigo explora estratégias para reduzir a carga tributária de pessoas jurídicas (PJ)..."
videos: ['https://www.youtube.com/embed/-Diu9SSMzjg?feature=oembed']
source: "blog_contabilizei"
processing_date: "2026-01-21 17:20:21"
---
# Como pagar menos impostos sendo PJ?
Para pagar menos impostos como PJ, é fundamental escolher o regime tributário mais vantajoso...
## O que é Fator-R?
O Fator-R é o cálculo utilizado para determinar a faixa de tributação de uma empresa...
| Faixa | Alíquota | Dedução |
| :--- | :--- | :--- |
| 1 | 6% | 0 |
| 2 | 11.2% | 9.360 |
## Vídeos Relacionados
- [Assistir Vídeo](https://www.youtube.com/embed/-Diu9SSMzjg?feature=oembed)
6. Guia de Operação
Pré-requisitos:
Python 3.10+
Arquivo .env na raiz com a chave: OPENAI_API_KEY=sk-...
Arquivo urls_blog.csv presente na pasta do script.
Como Executar o Pipeline
No terminal, execute o script principal:
python etl_blog_pipeline.py
O script exibirá logs em tempo real:
[PROCESS]: Iniciando uma nova URL.
[SKIP]: URL já processada anteriormente.
[SUCCESS]: Arquivo Markdown gerado com sucesso.
Podendo ser verificado qualquer erro no relatório gerado: "base_rag_blog/relatorio_execucao.md".
Este arquivo lista todas as linhas processadas e o status de cada uma (Sucesso, Erro de Layout, Página não encontrada, etc).